Earlier this year, I wrote about embedding column-name contracts in data pipelines with dbt. This, in turn, built off my post regarding the general theory of using controlled vocabularies to define data models.
The general idea of the post was:
- Column names are the “user interface” between data producers and consumers
- Standardizing a controlled vocabulary of naming “keywords” can communicate semantics and type information
- These names can then be operated on in code and aid in automated documentation, testing, and transformation
My first post illustrated these concepts using packages from R’s tidyverse. This suite of packages has an expressive, declarative API that inadvertently shaped a lot of my thinking around “naming things”. Clever naming schemes make things just work. The latter, as the name suggests, used SQL and dbt. While this too proved effective, it felt less elegant and satisfying. This inspired me: what if more dplyr syntax existed in dbt?
TLDR
This inspired the creation of the dbtplyr dbt package (find it on GitHub). This package aims to port the semantic sugar of dplyr’s select-helpers and related functionality to dbt to support both controlled vocabularies and, more broadly, more concise and semantic code.
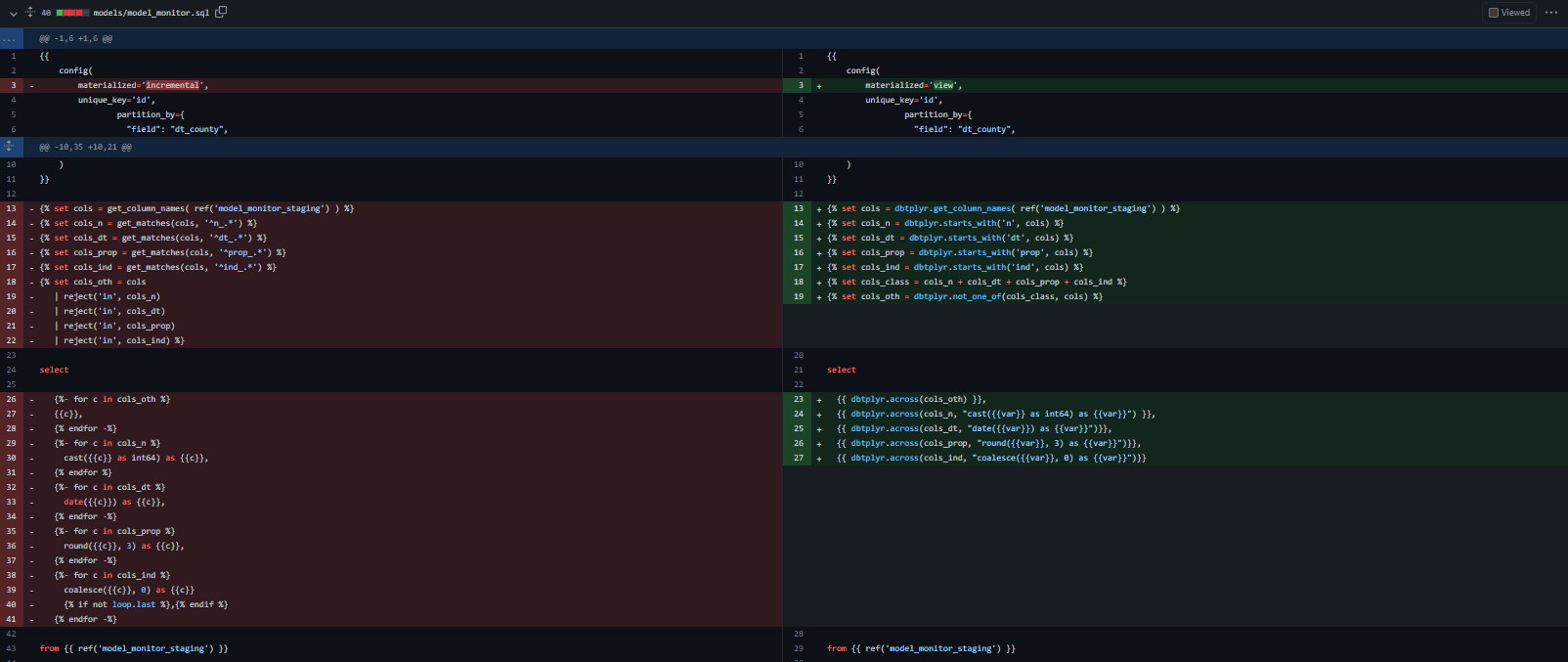
A full explanation is provided below. Additionally, for those that have read the previous post, I have also rewritten my COVID data modeling example to use the macros available in dbtplyr. Comparing the diff of the model_monitor model between the two versions illustrates how dbtplyr’s semantic sugar creates more concise and readable templating code.
Introducing dbtplyr
To paraphrase the README:
This add-on package enhances dbt by providing macros which programmatically select columns based on their column names. It is inspired by the across() function and the select helpers in the R package dplyr.
dplyr (>= 1.0.0) has helpful semantics for selecting and applying transformations to variables based on their names. For example, if one wishes to take the sum of all variables with name prefixes of N and the mean of all variables with name prefixes of IND in the dataset mydata, they may write:
summarize(
mydata,
across( starts_with('N'), sum),
across( starts_with('IND', mean)
)This package enables us to similarly write dbt data models with commands like:
{% set cols = dbtplyr.get_column_names( ref('mydata') ) %}
{% set cols_n = dbtplyr.starts_with('N', cols) %}
{% set cols_ind = dbtplyr.starts_with('IND', cols) %}
select
{{ dbtplyr.across(cols_n, "sum({{var}}) as {{var}}_tot") }},
{{ dbtplyr.across(cols_ind, "mean({{var}}) as {{var}}_avg") }}
from {{ ref('mydata') }}which dbt then compiles to standard SQL.
Alternatively, to protect against cases where no column names matched the pattern provided (e.g. no variables start with n so cols_n is an empty list), one may instead internalize the final comma so that it is only compiled to SQL when relevant by using the final_comma parameter of across.
{{ dbtplyr.across(cols_n, "sum({{var}}) as {{var}}_tot", final_comma = true) }}Note that, slightly more dplyr-like, you may also write:
select
{{ dbtplyr.across(dbtplyr.starts_with('N', ref('mydata')), "sum({{var}}) as {{var}}_tot") }},
{{ dbtplyr.across(dbtplyr.starts_with('IND', ref('mydata')), "mean({{var}}) as {{var}}_avg") }}
from {{ ref('mydata') }}But, as each function call is a bit longer than the equivalent dplyr code, I personally find the first form more readable.
The complete list of macros included are:
Functions to apply operation across columns
across(var_list, script_string, final_comma)c_across(var_list, script_string)
Functions to evaluation condition across columns
if_any(var_list, script_string)if_all(var_list, script_string)
Functions to subset columns by naming conventions
starts_with(string, relation or list)ends_with(string, relation or list)contains(string, relation or list)not_contains(string, relation or list)one_of(string_list, relation or list)not_one_of(string_list, relation or list)matches(string, relation)everything(relation)where(fn, relation)wherefnis the string name of a Column type-checker (e.g. “is_number”)
Note that all of the select-helper functions that take a relation as an argument can optionally be passed a list of names instead.
Documentation for these functions is available on the package website and in the macros/macro.yml file.