- title: Data cleaning and validation
description: >
We will conduct data quality checks,
resolve issues with data quality, and
document this process
due_on: 2018-12-31T12:59:59Z
issue:
- title: Define data quality standards
body: List out decision rules to check data quality
assignees: [emilyriederer]
labels: [a, b, c]
- title: Assess data quality
body: Use assertthat to test decision rules on dataset
labels: [low]
- title: Resolve data quality issues
body: Conduct needed research to resolve any issues
- title: Exploratory data analysis
description: >
Create basic statistics and views to better
understand dataset and relationships
issue:
- title: Summary statistics
body: Calculate summary statistics
- title: Visualizations
body: Create univariate and bivariate plotsMany tools and packages aim to eliminate the pain and uncertainty of technical project management. For example, git, make, Docker, renv, and drake are just a few existing tools that enable collaboration, manage softwatre dependencies, and promote reproducibility. However, there is no analogous gold standard for managing the most time-consuming and unpredictable depencies in data analysis work: our fellow humans.
This was my initial motivation for developing the projmgr R package. Earlier this year, I was delighted to receive an invitation to speak about this package at UseR!2020, but unfortunately the conference was rightly cancelled due to COVID-19 risk.
However, as the pandemic has pushed data teams towards remote work, the challenges of effective team communication and project management have become even more acute. Without the passive context sharing that comes through collocation, it’s easier for misunderstandings to arise either because stakeholders were misaligned from the outset or because their vision of a project independently drifts in different directions.
Overcommunication is key, but this in itself taxes productivity. Communication with our collaborators and customers is often spread across Zoom, email, Slack, GitHub, and sometimes third-party project management tools like Jira or Trello. Switching between these different software tools and frames of mind knocks analysts out of their flow and detracts from getting work done.
projmgr offers a solution: an opinionated interface for conducting end-to-end project management with R, using GitHub issues and milestones as the backend. Key features of this package include bulk generation of GitHub issues and milestones from a YAML project plan and automated creation of status updates with user-friendly text summaries and plots.
In this post, I summarize my would-have-been talk to highlight features of the package that are particularly useful in the current climate.
Project Management Goals
Comparing how we manage tools sheds some light on what is needed in a technical project management tool. Good practices from software engineering include:
- Establishing clear expectations both for our code (with unit and integration tests) and the environment (with Dockerfiles and dependency management)
- Ensuring new development aligns with the objective with version control and continuous integration
- Broadcasting updates through multiple mechanisms such as commit messages,
NEWS.mdfiles, semantic versioning, and (in the case of R in particular) CRAN’s reverse dependency checks
In contrast, in project management:
- Expectations can be ambiguous as we communicate with fluid, flexible language
- Priorities can change due to misunderstandings or private context (and without so much as a commit message to warn us!)
- Progress is not always observable without active effort from the performing team
All of these issues can be mitigated through proactive communication. However, any time spent making update decks or writing emails is time not spent on the next data product, model, or analysis. The beauty of many of our software developer tools is these features are largely automated and integrated into our workflows with minimal friction or time cost.
In the rest of this post, I will demonstrate how projmgr can be used to tackle these three challenges by: making a plan, assessing priorities, and sharing updates.
Making a Plan
The first step to project management is making a plan and getting buy-in from all relevant stakeholders, including target piees of work to deliver on different timelines. projmgr allows you to easily articulate a project plan in human-readable YAML and then seamlessly bulk-upload a set of GitHub issues and milestones.
For example, suppose in a data analysis, we write out the following plan and save it to the file plan.yml:
This format is fairly human-readable, accessible, and easy to edit. It can be shared with a team to get alignment.
Once a plan has been made, projmgr can read this into R as follows:
library(projmgr)
plan <- read_plan("plan.yml")To ensure our plan was read in correctly, we can print a quick summary:
planPlan:
1. Data cleaning and validation (3 issues)
2. Exploratory data analysis (2 issues) Next, we can create a connection to a GitHub repo and push our plan to the repo:
repo <- create_repo_ref(repo_owner = 'emilyriederer', repo_name = 'experigit')
post_plan(repo, plan)This results in the creation of the following set of issues and milestones:
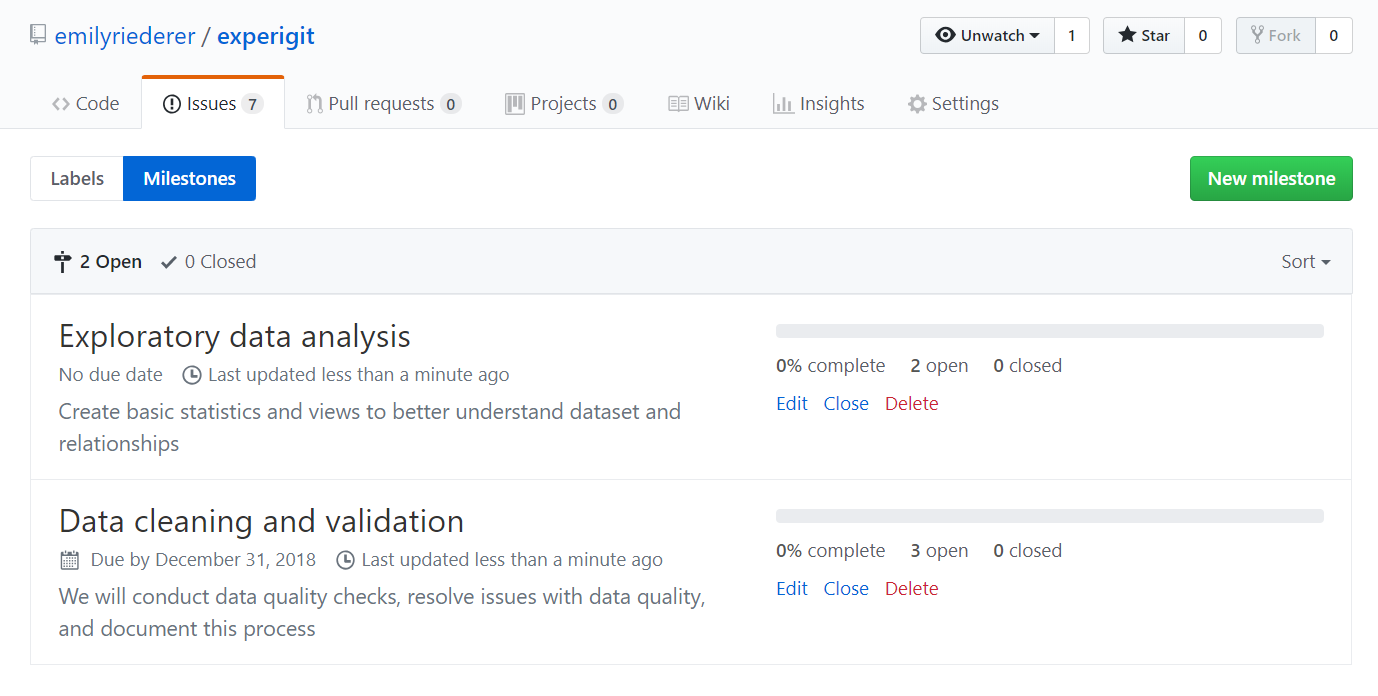
From there, we can continue to open, close, and comment on our issues as we would with any others.
Similarly, with read_todo() and post_todo(), you can send additional issues to your repository that aren’t nested under milestones.
Analyzing Priorities
Of course, the fun thing about plans is that plans can change. GitHub issues provide a flexible interface for projects to be dynamic and always open for commentary, feedback, requests, and new ideas. Beyond the issues created in our plan, we can use projmgr to understand organically occuring GitHub issues and to potentially incorporate them into our projects.
projmgr facilitates this by looking at issue metadata. Specifically, it can filter, extract, and pivot any type of custom label names. For example, let’s consider the RForwards/tasks repository.
forwards <- create_repo_ref("forwards", "tasks")
issues <- get_issues(forwards) %>% parse_issues()The labels_name column contains lists of entries. One common use of labels in this repo is to denote the team responsible for completing a task, denoted by the tag "{name}-team".
head(issues[, c('labels_name', 'number', 'title')]) labels_name number
1 survey-team 41
2 help wanted, survey-team 40
3 35
4 33
5 32
6 31
title
1 useR! 2018 survey analysis
2 Create new Community section on Data page
3 Guidelines on Ableist language in Talks and Presentations.
4 Rainbow R : LGBT+ in the R Community
5 Inviting R community and event organizers from Africa and Asia to the RUG slack.
6 Joint event with Trans*Codeunique(unlist(issues$labels_name))[1] "survey-team" "help wanted" "conferences-team"
[4] "admin" "on-ramps-team" "branding"
[7] "teaching-team" "social-media-team" "community-team" The listcol_filter() function lets us filter our data only to the isues relevant to a certain list column entry. For example, the data currently contains 26 issues. But we can filter down to those only assigned to any team or a specific team.
nrow(issues)[1] 26# any issue with a label ending in 'team'
listcol_filter(issues, "labels_name", matches = "-team$", is_regex = TRUE) %>% nrow()[1] 14# any issue with a label matching 'teaching-team'
listcol_filter(issues, "labels_name", matches = "teaching-team") %>% nrow()[1] 2Alternatively, we can create new columns by extracting data from our labels. For example, we can create a team column in our dataset by extracting the labels ending in "-team".
issues[, c('labels_name', 'number', 'title')] %>%
listcol_extract("labels_name", regex = "-team$") %>%
head() labels_name number
1 survey-team 41
2 help wanted, survey-team 40
3 35
4 33
5 32
6 31
title
1 useR! 2018 survey analysis
2 Create new Community section on Data page
3 Guidelines on Ableist language in Talks and Presentations.
4 Rainbow R : LGBT+ in the R Community
5 Inviting R community and event organizers from Africa and Asia to the RUG slack.
6 Joint event with Trans*Code
team
1 survey
2 survey
3 <NA>
4 <NA>
5 <NA>
6 <NA>Finally, the listcol_pivot() helped function identifies all labels matching a regex, extract all the “values” from the key-value pair, and pivots these into boolean columns. For example, the following code makes a widened dataframe with a separate column for each team. TRUE denotes the fact that that team is responsible for that issue.
issues_by_team <-
issues[, c('labels_name', 'number', 'title')] %>%
listcol_pivot("labels_name",
regex = "-team$",
transform_fx = function(x) sub("-team", "", x),
delete_orig = TRUE)
head(issues_by_team) number
1 41
2 40
3 35
4 33
5 32
6 31
title
1 useR! 2018 survey analysis
2 Create new Community section on Data page
3 Guidelines on Ableist language in Talks and Presentations.
4 Rainbow R : LGBT+ in the R Community
5 Inviting R community and event organizers from Africa and Asia to the RUG slack.
6 Joint event with Trans*Code
survey conferences on-ramps teaching social-media community
1 TRUE FALSE FALSE FALSE FALSE FALSE
2 TRUE FALSE FALSE FALSE FALSE FALSE
3 FALSE FALSE FALSE FALSE FALSE FALSE
4 FALSE FALSE FALSE FALSE FALSE FALSE
5 FALSE FALSE FALSE FALSE FALSE FALSE
6 FALSE FALSE FALSE FALSE FALSE FALSEThis has many convenient use-cases, including being able to quickly see the number falling into each category.
colSums(issues_by_team[, -c(1,2)]) survey conferences on-ramps teaching social-media community
4 1 3 2 2 2 Other examples of metadata that could be included as issue labels include subjective assessments of priority and difficulty (e.g. 'Priority: 1, 'Difficulty: Hard), the part of a project effected (e.g. stage:eda, stage:tuning), and much more. The only limit is the maintainer’s willingness to adhere to labelling conventions.
Reporting Progress
Once we are managing our project in GitHub, projmgr offers multiple ways to summarize progress.
We can retrieve issues from any repository with get_issues() (which returns the full results from the GitHub API) and parse_issues() (which structures particularly relevant columns into a dataframe). For example:
issues <- repo %>% get_issues() %>% parse_issues()We can use the report_progress() family of functions to share an update on the status of each issue, now linked back to the GitHub reposiitory.
report_progress(issues)Data cleaning and validation ( 100 % Complete - 3 / 3 )
Exploratory data analysis ( 50 % Complete - 1 / 2 )
Beyond simple text summaries, we can also share a number of visualizations such as Gantt charts or taskboards. To demonstrate this, I’ll switch to an example of a more complex set of issues, hypothetically pulled from GitHub and stored to as a data.frame in a variable called pkg_issues.
Using HTML and CSS grid, report_taskboard() function creates an aesethetic and interactive views of your work.
report_taskboard(pkg_issues, in_progress_when = is_assigned_to("emilyriederer"), hover = TRUE)Not Started
In Progress
Done
Extend report() support to LaTeX
Add get for events data
Add parse for events data
API mocking for testing
Validate YAML read from read fxs
Add browse and help functions
Write vignette to demo visualization
Add metadata function examples to vignettes
Add JSON support for plan / todo
report_taskboard() includes many different options including linking back to each individual issue and changing the colors of each column.
Not only is this visual summary more pleasant, but it also enables better insights for stakeholders by allowing you to flexibly share what work is being actively worked on at the moment (beyond simple open / closed status). This is controlled by the in_progress_when option and a number of helper function-factories to allow you to semantically described what constitutes progress. The above example uses the is_labeled_with() option. Other options include:
ls('package:projmgr')[grep("^is_*", ls('package:projmgr'))] [1] "is_assigned" "is_assigned_to" "is_created_before"
[4] "is_due" "is_due_before" "is_in_a_milestone"
[7] "is_in_milestone" "is_labeled" "is_labeled_with"
[10] "is_part_closed" Want to Learn More?
To learn more and explore other use cases and code flows, please check out the articles on the projmgr website. This showcases other features such as using projmgr to send emails1, coordinate hackathons, track KPIs, documenting conversations, and more.
This project is still under active development, and I welcome any ideas of new features via GitHub.
Footnotes
I have yet to test this with
blastula, but I hope to update the vignette with that in mind↩︎